
Hello I think there’s a lot of work involved when a PDF file is created on a web site. Probably a PDF file is the best for publishing on the internet. If the users are going to share Adobe Illustrator files or haves files to print, perhaps they’ll have to use the PDF format every time. Of course there’s a lot of similar work recently, but it’s very hard to debug a PDF file which was created with the client’s server development. Usually the developer has 3 methods for developing PDF files.
(1) Using print debug. You have to concentrate on seeing numbers and characters.
This is an easy way to debug the program code for the developer. However, you won’t be able to recognize the actual PDF file if you finish writing the final code until the end.
(2) Debugging the code while creating a log file on the server
You can confirm the variable live but it’s not realistic. You have to check the log file every time you debug. This method is troublesome.
(3) Using an authentic debugger.
If you can install the authentic debugger, you can debug efficiently, but you have to install the debugger software to your server and you might not be able to install it depending on the environment. Usually you can not install a specific software to the client’s server.
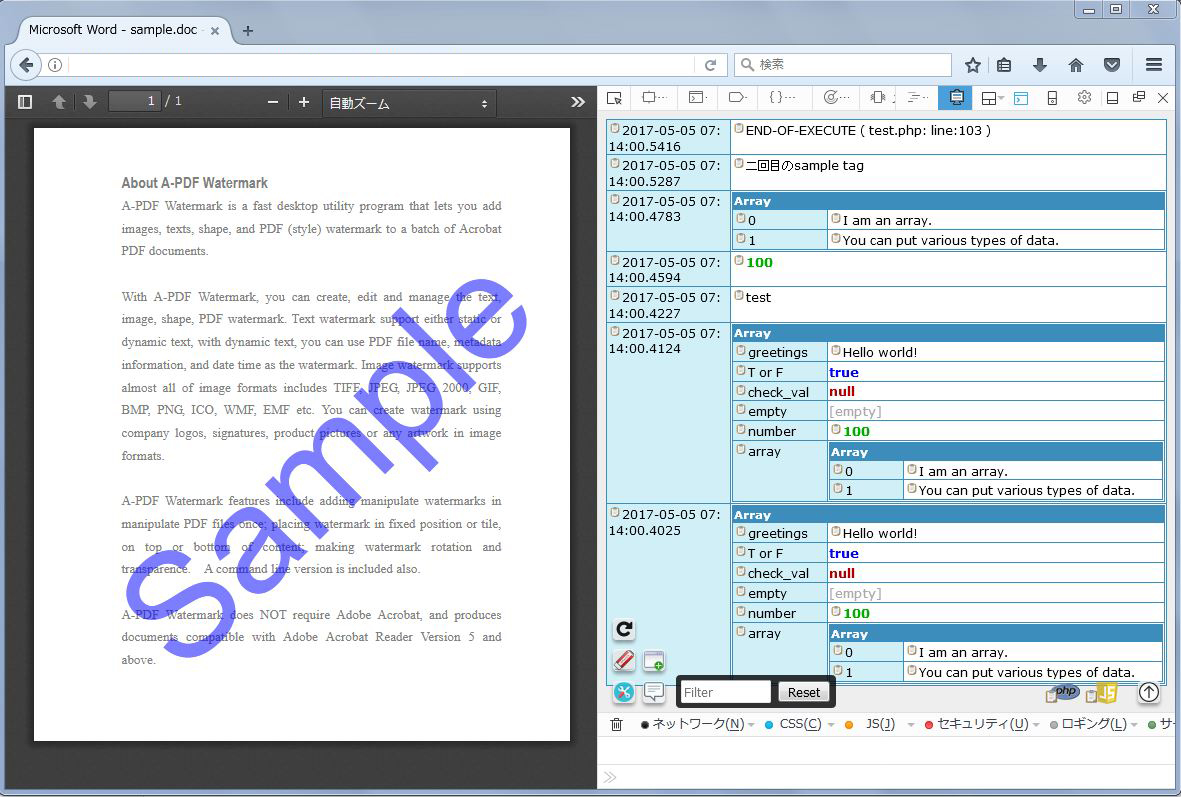
■Tentatively develop the code efficiently.
Let’s try using edump. You can use it easily since it’s at the same level as “print debug”.
![]()
You’ll be able to debug codes efficiently if you use edump and you won’t need to install any additional software to your server. You can prepare this authentic environment using your browser’s extension also as well as confirm various variables with the actual PDF file so it’s efficient in debugging.
Web developing is easy but sometimes you’ll encounter some difficulties. Every situation depends on the server’s environment. You have to select the most efficient environment with your programming language every time.